Atlas: Baidu分散式存儲系統
概述
設計目標
- 高效可靠地存儲海量小文件。文件大小為幾KB~幾MB,文件總數據量上百PB,並且高速增長,主要服務於百度雲盤;
- 追求高存儲效率,節省成本:伺服器成本、電力成本、數據存儲成本等。
手段
- 硬體定製
定製專屬存儲伺服器:去無用組件,基於ARM CPU的存儲機,2U存放6個機器, 每個機器4核、4GB內存(受限於CPU)、4個3T硬碟,2U共72TB存儲, 相比普通機架伺服器,存儲密度提升1倍。
- 軟體優化
受限於內存容量(4GB),無法使用Haystack的做法對每個對象在內存中緩存其元數據,採用LSM tree管理對象元數據;
使用糾刪碼而非複製技術提高數據可靠性; 強一致性模型;
本文章中我們主要討論軟體優化手段,對硬體不作過多描述。
內存使用
受限於存儲機伺服器內存,無法採用Haystack設計,將所有元數據緩存在內存中。做個計算,假如對象平均大小為128KB,單個伺服器存儲容量為16TB,每個對象元數據佔用26B(key: 16B, size: 4B, offset:4B, hash table entry: 2B),總內存消耗達到了16TB/128KB * 26B=3.25GB。
既然無法將所有的元數據緩存在內存中,那麼只能另想他法:LSM-tree。關於LSM-tree是什麼請自行google,另外其實現應該是採用了google出品的levelDB。在LSM-tree中KV有序存儲在內存和磁碟上。其每1MB的數據才需要20B的元數據存儲在內存,總的內存消耗大大降低,只有原來的10%,消耗內存約為320MB,這就在一個可接受範圍之內。
但這種做法雖然節約了內存,卻帶來元數據訪問時的性能下降。以前只需要在內存hash table中查找元數據,現在查找過程可能需要讀磁碟。
架構
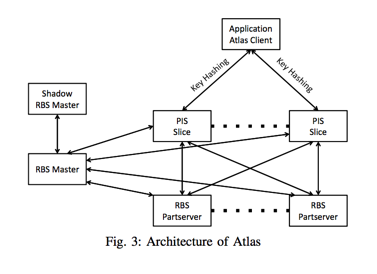
Atlas系統主要由以下幾部分組成:
- Client:讀寫客戶端,被鏈接至應用程序中;
- PIS Slice:負責數據的臨時存儲以及數據索引的管理;
- RBS System:由RBS Master和RBS PartServer組成,對數據作糾刪碼編碼並存儲。
Client
Client負責代理客戶執行讀取、寫入和刪除。應用程序key和value,客戶端根據key計算hash決定將其寫入哪個PIS Slice或者從哪個PIS Slice讀取。在Atlas中,key是根據value生成的一個特徵值(128b),如SHA-1。這個特點也就決定了Atlas系統要實現多副本的強一致性就必須要將所有的讀寫刪除請求發送到主副本。
PIS Slice
客戶端的寫入請求會被發往某個特定PIS Slice(系統的PIS Slice數目固定,每個PIS Slice是個集群,可橫向擴容)。每個PIS Slice內部結構如下圖所示:
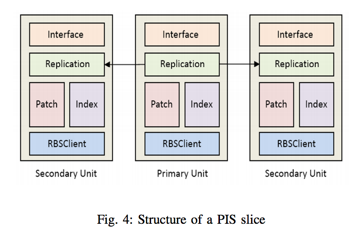
其中:
Patch模塊:負責應用程序數據的存儲,小對象會被合併存儲在Patch中。每個Patch最大為64MB,超過64MB會開啟新的Patch寫入;
Index模塊:負責追蹤對象在Patch中的位置信息,其記錄格式為(key, offset, size)。如前文所述,Index信息沒有已hash table方式緩存在內存中,而是使用LSM-tree方式存儲。另外,個人猜測,每個Patch會對應一個Index文件;
Replication模塊:負責數據在多副本之間的複製,在PIS slice內,數據依然使用多副本方式保證可靠性。對多副本的數據一致性協議,論文中未做過多描述,只是提及讀寫刪除均由Primary Unit處理(對於強一致性需求且key由客戶端生成就必須要這麼做)。
除此之外,PIS Slice沒有具體描述的還有一些元數據管理服務:如進行Slice的數據遷移等。
RBS
RBS負責將PIS的Block數據進行EC後存儲,PIS每個64MB的Block被切割成8個數據塊(8MB每個小塊),然後生成4個校驗塊,然後將這12個小數據塊存儲於RBS系統中。
RBS系統由元數據服務和數據服務組成,數據服務顧名思義即存儲Block被切割並計算校驗塊後的數據分片,而元數據服務則用來追蹤PIS中的Block在RBS中的存儲位置信息。
具體來說,PIS系統調用RBSClient向RBS中寫入Block數據,RBSClient處理過程:
- 向RBS元數據服務申請分配BlockID以及該Block存放的數據伺服器地址;
- RBS元數據服務返回可寫伺服器列表以及分配的BlockID;
- RBSClient向伺服器列表分別寫入數據切片;
- 寫入成功後,RBSClient向RBS元數據服務提交寫入結果;
- 刪除PIS上Block的三副本數據。
通過上述步驟,一個Block數據便從PIS轉移到RBS上,且三副本變成了8+4。
核心模塊
PIS Slice
PIS Slice內部主要由Patch和Index模塊組成。其中Patch主要負責數據存儲,而Index主要負責元數據(文件在Patch內的存儲位置等信息)存儲。這裡的關鍵是元數據到底怎麼存?
猜測實現:
當文件被追加寫入Patch Block時,同時將該文件在Patch中的元數據信息寫入Patch對應的index文件中,該index文件與patch文件一一對應,且該index文件很小(每個),完全可以緩存在內存中。Patch 為64MB,文件平均大小128KB,每個文件的元數據信息20B,總的元數據約20B* (64MB/128KB)=10KB,完全可以緩存在內存中。
當Patch Block被寫入至RBS系統中後,此時文件的元數據格式也有所變化,從原來的(key, offset, length) ==> (BlockID, offset, key) (BlockID由RBS Master服務生成)。

此時,PIS Slice系統將內存中Patch Block的元數據變換後(加上RBS分配的BlockID)寫入元數據存儲模塊Index中,且這些元數據也會通過replication模塊寫入從副本。Index其實就是LSM tree的一個實現,應該是百度基於LevelDB的修改版本。
當然,上面只是我根據論文作的合理猜測,具體實現不一定,不過感覺八九不離十。
關鍵問題
數據刪除
由於對小文件數據採取了追加存儲方式,因此,對於刪除無法做到實時:所有的刪除記錄也會被追加到Patch文件。
如果要刪除的文件位於當前active patch中,則直接將該文件的元數據記錄從Patch的in memory index中刪除,此時接下來對該文件的讀就變得不可見了,當然,數據還存在於patch中。這些數據會在接下來的垃圾回收過程中被回收掉。
如果要刪除的文件已經被寫入了RBS系統中,那麼此時從LSM index中刪除該文件的index。接下來就無法再讀到該數據了,同樣,數據會在接下來的垃圾回收過程被清理。
垃圾回收
因為Atlas的數據刪除屬於延遲刪除,刪除只是將其元數據刪除,被刪除數據佔據的空間依然被使用,垃圾回收就是要回收這部分無效空間。
Atlas的垃圾回收以Block為單位,且在一個離線系統的輔助下進行。垃圾回收需要解決以下幾個關鍵問題:
- 如何判定Block是否需要回收;
- 如何回收垃圾Block。
Block回收條件判定?
判定一個Block是否需要被回收其實一個基本方法就是計算該Block內被刪除的數據量的比例,如果超過某個閾值(如30%?),就認為該Block需要被回收。
此時問題就轉化為在現有系統中如何判斷Block內被刪除文件數(據量)!這個好辦,直接將PIS Slise所有的index數據全部拿過來,將每一條的(key,blockID,offset,len)變成(blockID, offset, len),這樣就可以統計出每個Block有效數據量,然後從RBS Master中拿到所有的Block創建時間信息。
這樣,我們就可以判斷:哪些Block有效數據量低於閾值且其存活時間已經超過一定範圍,我們就回收這樣的Block。
垃圾Block回收
Atlas回收垃圾Block過程:
- 從垃圾Block中讀出有效文件(未被刪除),並將有效文件寫入Atlas中;
- 垃圾Block有效數據全部寫入完成後,向RBS發起刪除Block請求。
RBS刪除Block處理流程:
- RBS master刪除Block信息,包括Block包含的數據分片;
- RBS data server定期和master交互信息,發現mds已經刪除了自己存儲的某些Block分片,於是將自己存儲的Block。
參考
- http://www.ece.eng.wayne.edu/~sjiang/pubs/papers/lai15-atlas.pdf
- http://www.bitstech.net/2015/07/25/baidu-atlas/#more-392
推薦閱讀:
※關於一致性協議的一些對比和總結
※CockroachDB和TiDB中的Multi Raft Group是如何實現的?
※raft協議疑問?
※分散式一致性演算法是如何解決少數派節點的寫順序一致性問題的?
※網路遊戲如何保證數據一致性?