Python數據挖掘實踐—KNN分類
1、最鄰近演算法
KNN方法的簡單描述:KNN方法用於分類,其基本思想如下。我們已經有一些已知類型的數據,暫稱其為訓練集。當一個新數據(暫稱其為測試集)進入的時候,開始跟訓練集數據中的每個數據點求距離,挑選與這個訓練數據集中最近的K個點看這些點屬於什麼類型,用少數服從多數的方法將測試數據歸類。

2、python實現最鄰近演算法案例
這裡我構造了一個150*5的矩陣,分別代表三類數據。每行的前四個值代表數據的特徵,第五個值代表數據的類別。如圖:
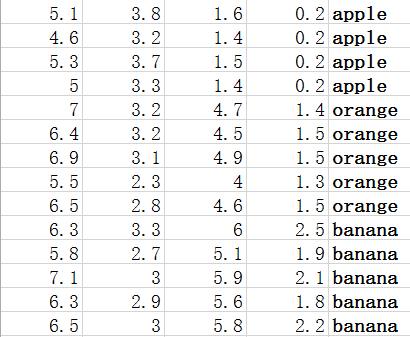
這三類數據分別屬於apple、banana、orange
第一步:載入數據。以split參數傳來的參數為限,將小於split的隨機數對應的數據劃分到訓練集,將大於split的隨機數劃分到測試集
def loadDataset(self,filename, split, trainingSet, testSet): # 載入數據集 split以某個值為界限分類train和test with open(filename, "r") as csvfile: lines = csv.reader(csvfile) #讀取所有的行 dataset = list(lines) #轉化成列表 for x in range(len(dataset)-1): for y in range(4): dataset[x][y] = float(dataset[x][y]) if random.random() < split: # 將所有數據載入到train和test中 trainingSet.append(dataset[x]) else: testSet.append(dataset[x])
第二步:對每個測試集中的數據進行迭代,取其臨近點。
計算測試集中每個點到訓練集中每個點的距離,將這些距離按從小到大進行排序,取最近的k個點作為歸類點
def getNeighbors(self,trainingSet, testInstance, k): # 返回最近的k個邊距 distances = [] length = len(testInstance)-1 for x in range(len(trainingSet)): #對訓練集的每一個數計算其到測試集的實際距離 dist = self.calculateDistance(testInstance, trainingSet[x], length) print("{}--{}".format(trainingSet[x], dist)) distances.append((trainingSet[x], dist)) distances.sort(key=operator.itemgetter(1)) # 把距離從小到大排列 neighbors = [] for x in range(k): #排序完成後取前k個距離 neighbors.append(distances[x][0]) return neighbors
計算距離函數
def calculateDistance(self,testdata, traindata, length): # 計算距離 distance = 0 # length表示維度 數據共有幾維 for x in range(length): distance += pow((testdata[x]-traindata[x]), 2) return math.sqrt(distance)
length表示維度,這裡數據是4維
第三步:判斷那k個點所屬的類別,選擇出現頻率最大的類標號作為測試集的類標號
def getResponse(self,neighbors): # 根據少數服從多數,決定歸類到哪一類 classVotes = {} for x in range(len(neighbors)): response = neighbors[x][-1] # 統計每一個分類的多少 if response in classVotes: classVotes[response] += 1 else: classVotes[response] = 1 print(classVotes.items()) sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) #reverse按降序的方式排列 return sortedVotes[0][0]
計算距離:


代碼和測試數據點這裡 :密碼:iaqr
如果嫌下載麻煩,這裡是全部code:
# -*- coding: UTF-8 -*-import mathimport csvimport randomimport operator"""@author:hunter@time:2017.03.31"""class KNearestNeighbor(object): def __init__(self): pass def loadDataset(self,filename, split, trainingSet, testSet): # 載入數據集 split以某個值為界限分類train和test with open(filename, "r") as csvfile: lines = csv.reader(csvfile) #讀取所有的行 dataset = list(lines) #轉化成列表 for x in range(len(dataset)-1): for y in range(4): dataset[x][y] = float(dataset[x][y]) if random.random() < split: # 將所有數據載入到train和test中 trainingSet.append(dataset[x]) else: testSet.append(dataset[x]) def calculateDistance(self,testdata, traindata, length): # 計算距離 distance = 0 # length表示維度 數據共有幾維 for x in range(length): distance += pow((testdata[x]-traindata[x]), 2) return math.sqrt(distance) def getNeighbors(self,trainingSet, testInstance, k): # 返回最近的k個邊距 distances = [] length = len(testInstance)-1 for x in range(len(trainingSet)): #對訓練集的每一個數計算其到測試集的實際距離 dist = self.calculateDistance(testInstance, trainingSet[x], length) print("訓練集:{}-距離:{}".format(trainingSet[x], dist)) distances.append((trainingSet[x], dist)) distances.sort(key=operator.itemgetter(1)) # 把距離從小到大排列 neighbors = [] for x in range(k): #排序完成後取前k個距離 neighbors.append(distances[x][0]) print(neighbors) return neighbors def getResponse(self,neighbors): # 根據少數服從多數,決定歸類到哪一類 classVotes = {} for x in range(len(neighbors)): response = neighbors[x][-1] # 統計每一個分類的多少 if response in classVotes: classVotes[response] += 1 else: classVotes[response] = 1 print(classVotes.items()) sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) #reverse按降序的方式排列 return sortedVotes[0][0] def getAccuracy(self,testSet, predictions): # 準確率計算 correct = 0 for x in range(len(testSet)): if testSet[x][-1] == predictions[x]: #predictions是預測的和testset實際的比對 correct += 1 print("共有{}個預測正確,共有{}個測試數據".format(correct,len(testSet))) return (correct/float(len(testSet)))*100.0 def Run(self): trainingSet = [] testSet = [] split = 0.75 self.loadDataset(r"testdata.txt", split, trainingSet, testSet) #數據劃分 print("Train set: " + str(len(trainingSet))) print("Test set: " + str(len(testSet))) #generate predictions predictions = [] k = 3 # 取最近的3個數據 # correct = [] for x in range(len(testSet)): # 對所有的測試集進行測試 neighbors = self.getNeighbors(trainingSet, testSet[x], k) #找到3個最近的鄰居 result = self.getResponse(neighbors) # 找這3個鄰居歸類到哪一類 predictions.append(result) # print(correct) accuracy = self.getAccuracy(testSet,predictions) print("Accuracy: " + repr(accuracy) + "%")if __name__ == "__main__": a = KNearestNeighbor() a.Run()
推薦閱讀: