指導行為--數據分析價值之源
我的R實踐:還是我們熟悉的《朝陽醫院2016年銷售數據》,課上我們做出了《2016年朝陽醫院消費曲線》及月均消費次數、月均消費金額、客單價等三個KPI指標。現在想想,這個結果除滿足院領導的顯擺欲,順道搭訕一下業務部門美女小夢外,並沒有什麼卵用。

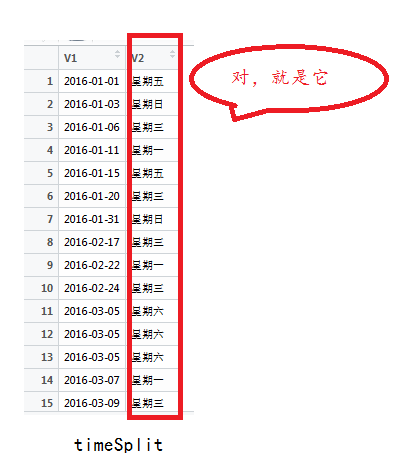
關鍵字 使用中文關鍵字「R語言 數據排序」,無論是谷哥還是百度,得到的結果基本都是sort(),rank(),order()三個函數的內容。正當我無計可施的時候,想起英文版的R語言實戰。閱讀它雖然還是沒有找到答案,但找到了"sort data"和"in R"兩個關鍵字。(見笑了,奇葩英語學習之路。這也算是英文版的另類用法吧!)
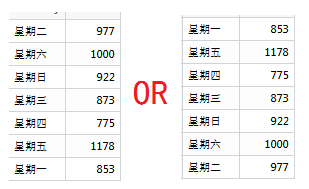
谷哥「How to sort data in R",我找到了提示,原來強在的R也有它小白的一面:想它給你排序,你得用factor()函數先告訴它」誰在先,誰在後「。
weekdaymoney$weekday <- factor(weekdaymoney$weekday,levels=c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"),ordered = T)


library(plyr) COUNT <- count(timeSplit,"timeSplit[,2]")
同時還計算了交易額和客單價的周變化情況,過程很順利,代碼如下:
weekdaymoney <-tapply(excelDate$actualmoney,excelDate$wd,sum)weekdaymoney$mean <- weekdaymoney$actualmoney/weekdaymoney$count
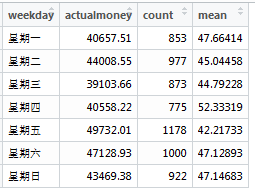



如果你是社保局的督查人員:星期四上班的醫院怎麼會事,都喜歡開大處方嘛?查
我的答案 首先聲明:上述解說純屬玩笑,但說明了一個意思:統計有什麼用?關鍵看是否使用統計結果指導行為。如果把統計結果與行為完全隔裂開來,那麼,統計真得沒有卵用。反之,統計就炸天了,它作用超乎你想像。同樣的數據在不同的人面前其價值是不一樣的。對於病人來說,可以指導更好地按排就診時間;對於一線排班人員,可以指導地安排人員作息;對於監查人員,可以有得放失高效開展督查……雖然價值各不相關,但它們產生價值的途徑卻是一至的,就是根據數據分析指導自己的行為。
我的代碼:
##第一大部分數據處理 #載入Excel數據 library(openxlsx) readFilePath <- "C:/朝陽醫院2016年銷售數據.xlsx" excelDate <- read.xlsx(readFilePath,1) #處理缺失數據 excelDate <- na.omit(excelDate) #數據框例重命名 names(excelDate) <- c("time","cardno","drugld","drugName","saleNumber","virtualmoney","actualmoney") #切割數據 library(stringr) timeSplit <- str_split_fixed(excelDate$time," ",n=2) WD <- data.frame(wd=timeSplit[,2]) excelDate <- cbind(excelDate,WD)##第二部分結果展示 library(plyr) COUNT <- count(timeSplit,"timeSplit[,2]") names(COUNT) <- c("weekday","count") weekdaymoney <-tapply(excelDate$actualmoney,excelDate$wd,sum) weekdaymoney <- as.data.frame.table(weekdaymoney) names(weekdaymoney) <- c("weekday","actualmoney") weekdaymoney <- merge(weekdaymoney,COUNT,by="weekday") weekdaymoney$weekday <- factor(weekdaymoney$weekday,levels=c("星期一","星期二","星期三","星期四","星期五","星期六","星期日"),ordered = T) weekdaymoney <- weekdaymoney[order(weekdaymoney$weekday),] weekdaymoney$mean <- weekdaymoney$actualmoney/weekdaymoney$count ##第三大部分結果展示 attach(weekdaymoney) layout(matrix(c(2,3,1,1),2,2,byrow=T)) weekdaymoney$Number <- c(1:7)##生成一周客單價變化情況圖 plot(weekdaymoney$Number,weekdaymoney$mean,xlab="",ylab="客單價",main="一周客單價變化情況圖",las=2,type="b",xaxt="n",bg="blue") axis(1,at=weekdaymoney$Number,labels=weekdaymoney$weekday,cex.axis=1.5) abline(h=mean(weekdaymoney$mean),col="red")#請左單擊滑鼠為紅線加標備 text(locator(1),"平均值")##生成一周交易量變化情況圖 plot(weekdaymoney$Number,weekdaymoney$count,xlab="",ylab="交易量",main="一周交易量變化情況圖",las=2,type="b",xaxt="n",lty=1,pch=23,bg="green") axis(1,at=weekdaymoney$Number,labels =weekdaymoney$weekday,cex.axis=1.5) abline(h=mean(weekdaymoney$count),col="red")#請左單擊滑鼠為紅線加標備 text(locator(1),"平均值")##生成一周交易額變化情況圖 plot(weekdaymoney$Number,weekdaymoney$actualmoney,xlab="",ylab="交易額",main="一周交易額變化情況圖",las=2,type="b",xaxt="n",lty=1,pch=23,bg="yellow") axis(1,at=weekdaymoney$Number,labels =weekdaymoney$weekday,cex.axis=1.5) abline(h=mean(weekdaymoney$actualmoney),col="red") #請左單擊滑鼠為紅線加標備 text(locator(1),"平均值") detach(weekdaymoney)
感謝:
謝謝您花時間讀到這裡,尤其是作出評論的親。數據分析學習之路,有您真好!
推薦閱讀: