Pandas | 表格整合三大神技之CONCATENATE
Pandas
pandas是(抄了R)基於(抄了MATLAB的)numpy搭建的、專門用於數據分析的Python工具箱。官網:Python Data Analysis Library
根據個人的一些使用經驗,Pandas相比於傳統的經濟學計算工具(Stata、SAS、R、MATLAB等)的優點有很多:
- 相比於R等統計軟體,Pandas借鑒了R的數據結構,因此擁有了R的很多方便的數據操作特性;在語法設計上,Pandas相比於R和Stata更嚴謹並且更簡潔易用;基於Python的自動管理內存的能力,以及在很多細節上的優化(比如在數據操作過程中數據複製和引用),Pandas擁有了更好的管理和計算大數據的能力。Python處理大數據的一個優秀案例:用Python Pandas處理億級數據
-Pandas的底層基於Numpy搭建,因此Pandas擁有了Numpy的全部優點,比如,Pandas定義的數據結構可以支持Numpy已經定義的計算,相當於擁有了MATLAB的矩陣計算能力;Numpy原生的C介面,也給擴展Pandas的計算性能帶來了很大的方便。
Pandas資料分享
- Pandas提供了大量和其他語言交互的介面(比如基於IO:IO Tools (Text, CSV, HDF5, ...),可視化:Visualization),再加上Python原生強大的膠水能力,Python+Pandas可以良好地與其他語言交互。
-Pandas官方文檔:pandas: powerful Python data analysis toolkit。 沒有比官方文檔更好的學習材料了。Pandas的文檔寫的非常清楚,並且Pandas的更新速度非常快,官方文檔以外的資料都會有很大的滯後。
-《Data Analysis with Python》:這本書是Pandas的作者寫的書,但是主要缺點是非常零散,不適合系統學習Pandas,建議粗略地看一遍用來了解Pandas的主要功能 or 數據處理的主要工作,之後遇到問題以後查閱官方文檔詳細學習。
CONCAT
pd.concat(objs, axis=0, join="outer", join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True)
objs : #輸入,可以是pandas Series格式組成的字典,DataFrame格式或list(多個合併).a sequence or mapping of Series, DataFrame, or Panel objects.
axis: {0, 1, ...}, default 0. #控制連接的方向,0代表列縱向,1代表行橫向
The axis to concatenate along.
join : {『inner』, 『outer』}, default 『outer』. #控制連接的索引,inner表示取表索引之間的交集,outer表示取索引的並集
How to handle indexes on other axis(es). Outer for union and innerfor intersection.
ignore_index: boolean, default False. #是否使用原索引,選捨棄便對新表重新進行索引排序。
If True, do not use the index values on the concatenation axis.
join_axes : list of Index objects. #設定使用的索引,例以df1的索引為標準,join_axes=[df1.index]
Specific indexes to use for the other n - 1 axes instead of performing inner/outer set logic.
keys : sequence, default None. #類似Multiindex,設立另一層索引
Construct hierarchical index using the passed keys as the outermost level. If
multiple levels passed, should contain tuples.
#暴走大事件四名同學的政治,英語,語文得分,索引為0,1,2,4(學號)df1=pd.DataFrame({"名字":["王尼瑪","張全蛋","趙鐵柱","李小花"], "語文":[95,88,23,66], "政治":[96,64,33,66], "英語":[66,100,33,66]} ,index=[0,1,2,4])
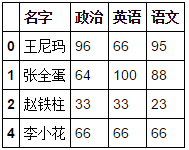
#NBA四名球員的失誤,籃板與英語得分,索引為1,2,3,5(球衣號)df2=pd.DataFrame({"名字":["哈登","科比","鄧肯","奧多姆"], "英語":[98,95,94,67], "籃板":[7,10,13,8], "失誤":[10,2,0,8]}, index=[1,2,3,5])
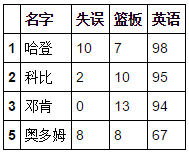
- 縱向合併兩表所有人與所有科目的得分,保持英語得分在同一列,並且標記暴走大事件與NBA為二層索引,標記缺失值為0.
frame=[df1,df2]df3=pd.concat(frame,keys=["暴走大事件","NBA"],axis=0,join="outer").fillna(0)
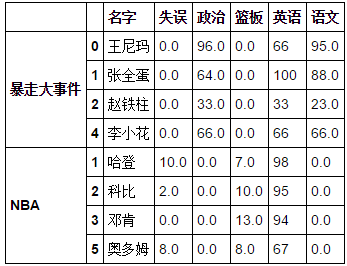
- 橫向合併兩表,僅比較索引相同的人(張全蛋趙鐵柱科比哈登),並且標記暴走大事件與NBA為二層索引
df4=pd.concat(frame,keys=["暴走大事件","NBA"],axis=1,join="inner")

APPEND
我們都知道APPEND常使用於list添加元素的情況中,在表格合併也可使用中APPEND,可以看做CONCAT簡易版,能夠在dataframe與series格式間使用和在縱向上連接。通常在某成熟表格添加額外行的情況下使用。
- 縱向合併(默認)兩表所有人與所有科目的得分,保持英語得分在同一列,標記缺失值為0,重排列索引.
df3=df1.append(df2,ignore_index=True).fillna(0)

本文同步發於集智(jizhi.im):[Pandas] 表格整合三大神技之CONCATENATE -,原文代碼可在線調試與訓練,方便各位小夥伴練習~
更多關於python數據分析與挖掘內容請關注我的專欄:數與碼
或者關注我的知乎賬號:知行
希望觀眾老爺們能夠喜歡
求贊求關注,會有敬業福~
thx
推薦閱讀:
※DBN中的RBM可以看作是先對數據進行無監督聚類,那麼這種聚類和K-MEANS等有什麼區別?具體是怎麼實現的?
※通過文本挖掘看歷史