FCN 的簡單實現
學習了沐神的 gluon 課程,覺得裡面有關於 fcn 的課程 特別有用,於是總結一下,同時使用 pytorch 重新實現,不僅實現 gluon 教程中的部分,同時實現論文中更精細的形式。
介紹
語義分割是一種像素級別的處理圖像方式,對比於目標檢測其更加精確,能夠自動從圖像中劃分出對象區域並識別對象區域中的類別,比如下面這個效果

上面是輸入的圖片,下面是希望得到的效果,也就是希望能夠對區域進行像素級別的劃分
在 2015 年 CVPR 的一篇論文 Fully Convolutional Networks for Semantic Segmentation 這篇文章提出了全卷積的概念,第一次將端到端的卷積網路推廣到了語義分割的任務當中,隨後出現了很多基於 FCN 實現的網路結構,比如 U-Net 等。
數據集
首先我們需要下載數據集,這裡我們使用 PASCAL VOC 數據集,其是一個正在進行的目標檢測,目標識別,語義分割的挑戰,我們可以進行數據集的下載
下載完成數據集之後進行解壓,我們可以在 ImageSets/Segmentation/train.txt 和 ImageSets/Segmentation/val.txt 中找到我們的訓練集和驗證集的數據,圖片存放在 /JPEGImages 中,後綴是 .jpg,而 label 存放在 /SegmentationClass 中,後綴是 .png
我們可以可視化一下

首先輸出圖片的大小,左邊就是真實的圖片,右邊就是分割之後的結果
然後我們定義一個函數進行圖片的讀入,根據 train.txt 和 val.txt 中的文件名進行圖片讀入,我們不需要這一步就讀入圖片,只需要知道圖片的路徑,之後根據圖片名稱生成 batch 的時候再讀入圖片,並做一些數據預處理
voc_root = "./data/VOCdevkit/VOC2012"def read_images(root=voc_root, train=True): txt_fname = root + "/ImageSets/Segmentation/" + ("train.txt" if train else "val.txt") with open(txt_fname, "r") as f: images = f.read().split() data = [os.path.join(root, "JPEGImages", i+".jpg") for i in images] label = [os.path.join(root, "SegmentationClass", i+".png") for i in images] return data, label
數據預處理
可能你已經注意到了前面展示的兩張圖片的大小是不一樣的,如果我們要使用一個 batch 進行計算,我們需要圖片的大小保持一致,在前面使用卷積網路進行圖片分類的任務中,我們通過 resize 的辦法對圖片進行了縮放,使得他們的大小相同,但是這裡會遇到一個問題,對於輸入圖片我們當然可以 resize 成任意我們想要的大小,但是 label 也是一張圖片,且是在 pixel 級別上的標註,所以我們沒有辦法對 label 進行有效的 resize 似的其也能達到像素級別的匹配,所以為了使得輸入的圖片大小相同,我們就使用 crop 的方式來解決這個問題,也就是從一張圖片中 crop 出固定大小的區域,然後在 label 上也做同樣方式的 crop。
使用 crop 可以使用 pytorch 中自帶的 transforms,不過要稍微改一下,不僅輸出 crop 出來的區域,同時還要輸出對應的坐標便於我們在 label 上做相同的 crop
def rand_crop(data, label, height, width): """ data is PIL.Image object label is PIL.Image object """ data, rect = tfs.RandomCrop((height, width))(data) label = tfs.FixedCrop(*rect)(label) return data, label
下面我們可以驗證一下隨機 crop

上面就是我們做兩次隨機 crop 的結果,可以看到圖像和 label 能夠完美的對應起來
接著我們根據數據知道裡面有 21 中類別,同時給出每種類別對應的 RGB 值
classes = ["background","aeroplane","bicycle","bird","boat", "bottle","bus","car","cat","chair","cow","diningtable", "dog","horse","motorbike","person","potted plant", "sheep","sofa","train","tv/monitor"]# RGB color for each classcolormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128], [128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0], [64,128,0],[192,128,0],[64,0,128],[192,0,128], [64,128,128],[192,128,128],[0,64,0],[128,64,0], [0,192,0],[128,192,0],[0,64,128]]len(classes), len(colormap)
接著可以建立一個索引,也就是將一個類別的 RGB 值對應到一個整數上,通過這種一一對應的關係,能夠將 label 圖片變成一個矩陣,矩陣和原圖片一樣大,但是只有一個通道數,也就是 (h, w) 這種大小,裡面的每個數值代表著像素的類別
cm2lbl = np.zeros(256**3) # 每個像素點有 0 ~ 255 的選擇,RGB 三個通道for i,cm in enumerate(colormap): cm2lbl[(cm[0]*256+cm[1])*256+cm[2]] = i # 建立索引def image2label(im): data = np.array(im, dtype="int32") idx = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2] return np.array(cm2lbl[idx], dtype="int64") # 根據索引得到 label 矩陣
定義完成之後,我們可以驗證一下
label_im = Image.open("./data/VOCdevkit/VOC2012/SegmentationClass/2007_000033.png").convert("RGB")label = image2label(label_im)label[150:160, 240:250]

array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
可以看到上面的像素點由 0 和 1 構成,0 表示背景,1 表示 飛機這個類別
接著我們可以定義數據預處理方式,之前我們讀取的數據只有文件名,現在我們開始做預處理,非常簡單,首先隨機 crop 出固定大小的區域,然後使用 ImageNet 的均值和方差做標準化。
def img_transforms(im, label, crop_size): im, label = rand_crop(im, label, *crop_size) im_tfs = tfs.Compose([ tfs.ToTensor(), tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) im = im_tfs(im) label = image2label(label) label = torch.from_numpy(label) return im, label
最後我們定義一個 COVSegDataset 繼承於 `torch.utils.data.Dataset` 構成我們自定的訓練集
class VOCSegDataset(Dataset): """ voc dataset """ def __init__(self, train, crop_size, transforms): self.crop_size = crop_size self.transforms = transforms data_list, label_list = read_images(train=train) self.data_list = self._filter(data_list) self.label_list = self._filter(label_list) print("Read " + str(len(self.data_list)) + " images") def _filter(self, images): # 過濾掉圖片大小小於 crop 大小的圖片 return [im for im in images if (Image.open(im).size[1] >= self.crop_size[0] and Image.open(im).size[0] >= self.crop_size[1])] def __getitem__(self, idx): img = self.data_list[idx] label = self.label_list[idx] img = Image.open(img) label = Image.open(label).convert("RGB") img, label = self.transforms(img, label, self.crop_size) return img, label def __len__(self): return len(self.data_list)
# 實例化數據集input_shape = (320, 480)voc_train = VOCSegDataset(True, input_shape, img_transforms)voc_test = VOCSegDataset(False, input_shape, img_transforms)train_data = DataLoader(voc_train, 64, shuffle=True, num_workers=4)valid_data = DataLoader(voc_test, 128, num_workers=4)
```
fcn 模型
fcn 模型非常簡單,裡面全部是由卷積構成的,所以被稱為全卷積網路,同時由於全卷積的特殊形式,因此可以接受任意大小的輸入,網路的示意圖如下

對於任何一張輸入圖片,由於卷積層和池化層的不斷作用,得到的輸出形狀會越來越小,但是通道數會越來越大,比如 ResNet18,會將輸入的長寬減小 32 倍,由 3x244x244 變成 512x7x7,也就是上圖的第一部分,得到的特徵圖會特別小,最後通過一個轉置卷積得到一個和輸入形狀一樣的結果,這裡我們引入了轉置卷積的概念,下面我們講一講什麼是轉置卷積
轉置卷積
我們首先可以看看下面的動畫

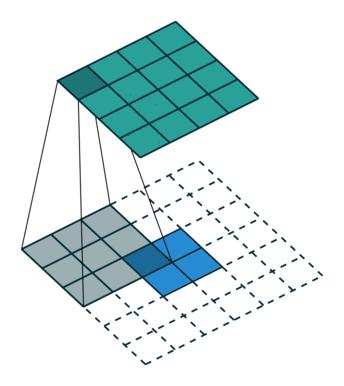
第一張就是我們常說的卷積的效果,而轉置卷積就是下面這個操作,相當於卷積的逆過程,將卷積的輸入和輸出反過來,卷積的正向傳播相當於圖片左乘一個矩陣 c,反向傳播相當於左乘 $c^T$,而轉置卷積的正向過程相當於左乘 $c^T$,反向過程相當於左乘 $(c^T)^T = c$,詳細的推導可以看看論文
而轉置卷積的計算公式也非常簡單,對於卷積
轉置卷積就是將輸入和輸出反過來,即
如果我們希望輸出變成輸入的兩倍,那麼 stride 取 2,kernel 和 padding 可以對應著取,比如 kernel 取 4,那麼 padding 就取 1
在 pytorch 中轉置卷積可以使用 torch.nn.ConvTranspose2d() 來實現,下面我們舉個例子
x = torch.randn(1, 3, 120, 120)conv_trans = nn.ConvTranspose2d(3, 10, 4, stride=2, padding=1)y = conv_trans(Variable(x))print(y.shape)
torch.Size([1, 10, 240, 240])
可以看到輸出變成了輸入的 2 倍
模型結構
最簡單的 fcn 前面是一個去掉全連接層的預訓練網路,然後將去掉的全連接變為 1x1 的卷積,輸出和類別數目相同的通道數,比如 voc 數據集是 21 分類,那麼輸出的通道數就是 21,然後最後接一個轉置卷積將結果變成輸入的形狀大小,最後在每個 pixel 上做一個分類問題,使用交叉熵作為損失函數就可以了。
當然這樣的模型是特別粗糙的,因為最後一步直接將圖片擴大了 32 倍,所以論文中有一個改進,就是將網路中間的輸入聯合起來進行轉置卷積,這樣能夠依賴更多的信息,所以可以得到更好的結果,可以看看下面的圖示

fcn-32s 就是直接將最後的結果通過轉置卷積擴大 32 倍進行輸出,而 fcn-16x 就是聯合前面一次的結果進行 16 倍的輸出,fcn-8x 就是聯合前面兩次的結果進行 8 倍的輸出,我們用上圖中 fcn-8x 舉例,就是先將最後的結果通過轉置卷積擴大 2 倍,然後和 pool4 的結果相加,然後在通過轉置卷積擴大 2 倍,然後和 pool3 的結果相加,最後通過轉置卷積擴大 8 倍得到和輸入形狀一樣大的結果。
bilinear kernel
通常我們訓練的時候可以隨機初始化權重,但是在 fcn 的網路中,使用隨機初始化的權重將會需要大量的時間進行訓練,所以我們卷積層可以使用在 imagenet 上預訓練的權重,那麼轉置卷積我們使用什麼樣的初始權重呢?這裡就要用到 bilinear kernel。
我們可以看看下面的例子
# 定義 bilinear kerneldef bilinear_kernel(in_channels, out_channels, kernel_size): """ return a bilinear filter tensor """ factor = (kernel_size + 1) // 2 if kernel_size % 2 == 1: center = factor - 1 else: center = factor - 0.5 og = np.ogrid[:kernel_size, :kernel_size] filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor) weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype="float32") weight[range(in_channels), range(out_channels), :, :] = filt return torch.from_numpy(weight)x = Image.open("./data/VOCdevkit/VOC2012/JPEGImages/2007_005210.jpg")x = np.array(x)plt.imshow(x)print(x.shape)
(281, 500, 3)

x = torch.from_numpy(x.astype("float32")).permute(2, 0, 1).unsqueeze(0)# 定義轉置卷積conv_trans = nn.ConvTranspose2d(3, 3, 4, 2, 1)# 將其定義為 bilinear kernelconv_trans.weight.data = bilinear_kernel(3, 3, 4)y = conv_trans(Variable(x)).data.squeeze().permute(1, 2, 0).numpy()plt.imshow(y.astype("uint8"))print(y.shape)
(562, 1000, 3)

可以看到通過雙線性的 kernel 進行轉置卷積,圖片的大小擴大了一倍,但是圖片看上去仍然非常的清楚,所以這種方式的上採樣具有很好的效果
下面我們使用 resnet 34 代替論文中的 vgg 實現 fcn
# 使用預訓練的 resnet 34pretrained_net = model_zoo.resnet34(pretrained=True)num_classes = len(classes)
這裡我們去掉最後的 avgpool 和 fc 層,使用 list(pretrained_net.children())[:-2] 就能夠取到倒數第三層
下面我們開始定義我們的網路結構,就像上面顯示的一樣,我們會取出最後的三個結果進行合併
class fcn(nn.Module): def __init__(self, num_classes): super(fcn, self).__init__() self.stage1 = nn.Sequential(*list(pretrained_net.children())[:-4]) # 第一段 self.stage2 = list(pretrained_net.children())[-4] # 第二段 self.stage3 = list(pretrained_net.children())[-3] # 第三段 self.scores1 = nn.Conv2d(512, num_classes, 1) self.scores2 = nn.Conv2d(256, num_classes, 1) self.scores3 = nn.Conv2d(128, num_classes, 1) self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False) self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16) # 使用雙線性 kernel self.upsample_4x = nn.ConvTranspose2d(num_classes, num_classes, 4, 2, 1, bias=False) self.upsample_4x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用雙線性 kernel self.upsample_2x = nn.ConvTranspose2d(num_classes, num_classes, 4, 2, 1, bias=False) self.upsample_2x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用雙線性 kernel def forward(self, x): x = self.stage1(x) s1 = x # 1/8 x = self.stage2(x) s2 = x # 1/16 x = self.stage3(x) s3 = x # 1/32 s3 = self.scores1(s3) s3 = self.upsample_2x(s3) s2 = self.scores2(s2) s2 = s2 + s3 s1 = self.scores3(s1) s2 = self.upsample_4x(s2) s = s1 + s2 s = self.upsample_8x(s2) return s
接著我們定義一些語義分割常用的指標,比如 overal accuracy,mean IU 等等,下面這個是參考 wkentaro 的 pytorch-fcn 得到的
def _fast_hist(label_true, label_pred, n_class): mask = (label_true >= 0) & (label_true < n_class) hist = np.bincount( n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class) return histdef label_accuracy_score(label_trues, label_preds, n_class): """Returns accuracy score evaluation result. - overall accuracy - mean accuracy - mean IU - fwavacc """ hist = np.zeros((n_class, n_class)) for lt, lp in zip(label_trues, label_preds): hist += _fast_hist(lt.flatten(), lp.flatten(), n_class) acc = np.diag(hist).sum() / hist.sum() acc_cls = np.diag(hist) / hist.sum(axis=1) acc_cls = np.nanmean(acc_cls) iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)) mean_iu = np.nanmean(iu) freq = hist.sum(axis=1) / hist.sum() fwavacc = (freq[freq > 0] * iu[freq > 0]).sum() return acc, acc_cls, mean_iu, fwavacc
然後我們定義 loss,這裡使用 torch.nn.NLLLoss2d(),其實這和交叉熵一樣,都是處理分類問題的 loss,只是這個 loss 需要在最後一層輸出加上 torch.nn.functional.log_softmax,但是這個 loss 可以作用在 2d 的輸出上,於是我們就選擇這個 loss
# 定義 loss 和 optimizerfrom mxtorch.trainer import ScheduledOptimcriterion = nn.NLLLoss2d()basic_optim = torch.optim.SGD(net.parameters(), lr=1e-2, weight_decay=1e-4)optimizer = ScheduledOptim(basic_optim)
訓練
for e in range(80): if e > 0 and e % 50 == 0: optimizer.set_learning_rate(optimizer.learning_rate * 0.1) train_loss = 0 train_acc = 0 train_acc_cls = 0 train_mean_iu = 0 train_fwavacc = 0 prev_time = datetime.now() net = net.train() for data in train_data: im = Variable(data[0].cuda()) label = Variable(data[1].cuda()) # forward out = net(im) out = F.log_softmax(out, dim=1) # (b, n, h, w) loss = criterion(out, label) # backward optimizer.zero_grad() loss.backward() optimizer.step() train_loss += loss.data[0] label_pred = out.max(dim=1)[1].data.cpu().numpy() label_true = label.data.cpu().numpy() for lbt, lbp in zip(label_true, label_pred): acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes) train_acc += acc train_acc_cls += acc_cls train_mean_iu += mean_iu train_fwavacc += fwavacc net = net.eval() eval_loss = 0 eval_acc = 0 eval_acc_cls = 0 eval_mean_iu = 0 eval_fwavacc = 0 for data in valid_data: im = Variable(data[0].cuda(), volatile=True) label = Variable(data[1].cuda(), volatile=True) # forward out = net(im) out = F.log_softmax(out, dim=1) loss = criterion(out, label) eval_loss += loss.data[0] label_pred = out.max(dim=1)[1].data.cpu().numpy() label_true = label.data.cpu().numpy() for lbt, lbp in zip(label_true, label_pred): acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes) eval_acc += acc eval_acc_cls += acc_cls eval_mean_iu += mean_iu eval_fwavacc += fwavacc cur_time = datetime.now() h, remainder = divmod((cur_time - prev_time).seconds, 3600) m, s = divmod(remainder, 60) epoch_str = ("Epoch: {}, Train Loss: {:.5f}, Train Acc: {:.5f}, Train Mean IU: {:.5f}, Valid Loss: {:.5f}, Valid Acc: {:.5f}, Valid Mean IU: {:.5f} ".format( e, train_loss / len(train_data), train_acc / len(voc_train), train_mean_iu / len(voc_train), eval_loss / len(valid_data), eval_acc / len(voc_test), eval_mean_iu / len(voc_test))) time_str = "Time: {:.0f}:{:.0f}:{:.0f}".format(h, m, s) print(epoch_str + time_str + " lr: {}".format(optimizer.learning_rate))
Epoch: 77, Train Loss: 0.23017, Train Acc: 0.92420, Train Mean IU: 0.64684, Valid Loss: 0.39680, Valid Acc: 0.87509, Valid Mean IU: 0.53005 Time: 0:0:41 lr: 0.001 Epoch: 78, Train Loss: 0.23212, Train Acc: 0.92334, Train Mean IU: 0.64237, Valid Loss: 0.39651, Valid Acc: 0.87538, Valid Mean IU: 0.52885 Time: 0:0:41 lr: 0.001 Epoch: 79, Train Loss: 0.23251, Train Acc: 0.92364, Train Mean IU: 0.64002, Valid Loss: 0.39242, Valid Acc: 0.87575, Valid Mean IU: 0.53311 Time: 0:0:41 lr: 0.001
可以看到,我們的模型在訓練集上的 mean IU 達到了 0.64 左右,驗證集上的 mean IU 達到了 0.53 左右,下面我們可視化一下最後的結果
# 定義預測函數cm = np.array(colormap).astype("uint8")def predict(im, label): # 預測結果 im = Variable(im.unsqueeze(0)).cuda() out = net(im) pred = out.max(1)[1].squeeze().cpu().data.numpy() pred = cm[pred] return pred, cm[label.numpy()]_, figs = plt.subplots(6, 3, figsize=(12, 10))for i in range(6): test_data, test_label = voc_test[i] pred, label = predict(test_data, test_label) figs[i, 0].imshow(Image.open(voc_test.data_list[i])) figs[i, 0].axes.get_xaxis().set_visible(False) figs[i, 0].axes.get_yaxis().set_visible(False) figs[i, 1].imshow(label) figs[i, 1].axes.get_xaxis().set_visible(False) figs[i, 1].axes.get_yaxis().set_visible(False) figs[i, 2].imshow(pred) figs[i, 2].axes.get_xaxis().set_visible(False) figs[i, 2].axes.get_yaxis().set_visible(False)

可以看到,通過訓練,模型已經有了基本效果,但是離論文中的效果有差距,有可能是訓練的問題,更多的原因應該是沒有使用 caffe model 中的 vgg 模型,這裡特別提醒一下,如果要使用 caffe model,那麼圖像預處理的時候要是 BRG 的格式,同時大小是 0 ~ 255,減去均值。
另外代碼中使用的 mxtorch 可以在我的 github 主頁看到
本文的代碼
歡迎查看我的知乎專欄 深度煉丹
歡迎訪問我的博客
推薦閱讀:
※pytorch中nn和nn.functional有什麼區別?
※2017 年 8 月 6 日發布的 pytorch 0.2.0 哪個特性最吸引你?
※如何有效地閱讀PyTorch的源代碼?
TAG:PyTorch | 深度学习DeepLearning |